一致性哈希算法是一种分布式哈希算法,它可以在节点动态添加或删除的情况下,保持数据的分布不变。这种算法广泛应用于分布式缓存、负载均衡和数据分片等领域。本文将详细介绍一致性哈希算法的原理和应用。
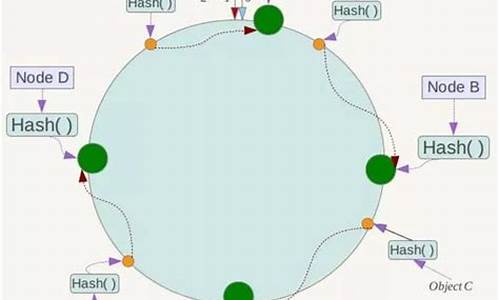
一致性哈希算法的基本原理是将数据映射到一个环形空间上,然后通过哈希函数计算每个数据在环形空间上的索引位置。当节点动态添加或删除时,只需要重新计算加入该节点的数据的哈希值,并将其映射到新的索引位置即可。这样可以保证数据的分布不会受到影响。
具体来说,一致性哈希算法需要以下几个步骤:
1. 将所有数据映射到一个环形空间上。这个环形空间的大小通常是一个素数,以避免出现“空洞”或“重叠”。
2. 通过哈希函数计算每个数据在环形空间上的索引位置。哈希函数的选择非常重要,需要选择一个好的哈希函数才能保证数据的分布不会受到影响。
3. 当节点动态添加或删除时,只需要重新计算加入该节点的数据的哈希值,并将其映射到新的索引位置即可。这样可以保证数据的分布不会受到影响。
一致性哈希算法的应用非常广泛。其中最常见的应用是分布式缓存。在分布式缓存中,多个节点共享同一个存储空间,但是由于存储空间有限,不能同时存储所有的数据。通过一致性哈希算法可以将数据分布在不同的节点上,从而实现负载均衡和容错。
另一个常见的应用是数据分片。在数据分片中,一个大表被分成多个小表,每个小表存储在不同的节点上。通过一致性哈希算法可以将数据均匀地分布在各个节点上,从而提高查询效率和降低延迟。
一致性哈希算法是一种非常实用的分布式算法,它可以在节点动态添加或删除的情况下保持数据的分布不变。在实际应用中,我们需要根据具体情况选择合适的哈希函数和环形空间大小,以保证数据的分布符合要求。







